前言 Spring 最重要的功能就是帮助程序员创建对象(也就是IOC),而启动 Spring 就是为创建 Bean 对象做准备,所以我们先明白 Spring 到底是怎么去创建 Bean 的,也就是先弄明白 Bean 的生命周期。
Bean的生命周期就是指:在Spring中,一个Bean是如何生成的,如何销毁的 。
Spring 在真正去实例化一个 bean 的时候是根据对应的 BeanDefinition 去处理的,所以首先就是要知道 BeanDefinition 是怎么生成的,这个流程也就是 Bean 的扫描流程。
Spring自动扫描注解方式 Spring 容器加载方式主要有以下3种:
xml配置文件方式 ClassPathXmlApplicationContext 扫描注解方式 AnnotationConfigApplicationContext 本地配置文件 FileSystemXmlApplicationContext 我们平常使用 Spring可以通过 @ComponentScan 注解可以声明自动注入要扫描的包,Spring 会将该包下所有加了 @Component 注解的 Bean 扫描到 Spring 容器中,也可以 通过 xml 文件来配置要扫描的 Bean,不过现在 SpringBoot 一般都是用 @ComponentScan 注解的方式,所以这里主要介绍自动扫描注解的流程。
Bean扫描流程分析 之前提过,Spring 中的 “Hello world” 如下:
1
2
3
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext( BeanScanConfig. class );
HelloWorldService service = ( HelloWorldService) context. getBean ( "helloWorldService" );
service. sayHello ();
上述几行代码实现了 Bean 的扫描和实例化。
首先就是容器的初始化,即:
1
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext( BeanScanConfig. class );
容器初始化 来看类 AnnotationConfigApplicationContext 的初始化,类 AnnotationConfigApplicationContext 源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public class AnnotationConfigApplicationContext extends GenericApplicationContext implements AnnotationConfigRegistry {
private final AnnotatedBeanDefinitionReader reader;
private final ClassPathBeanDefinitionScanner scanner;
public AnnotationConfigApplicationContext () {
StartupStep createAnnotatedBeanDefReader = this . getApplicationStartup (). start ( "spring.context.annotated-bean-reader.create" );
this . reader = new AnnotatedBeanDefinitionReader( this );
createAnnotatedBeanDefReader. end ();
this . scanner = new ClassPathBeanDefinitionScanner( this );
}
public AnnotationConfigApplicationContext ( Class<?>... componentClasses) {
this ();
register( componentClasses);
refresh();
}
}
一开始,会执行带参数的构造函数,然后调用无参构造函数。StartupStep 是用来统计耗时的,这里不做具体分析。
this.reader = new AnnotatedBeanDefinitionReader(this); 这里用于传入指定 bean 的类的时候使用,会直接进行 BeanDefinition 的注册。注意这里传入的是 this 参数。
实际上,不管是直接指定 bean 的类进行注册还是扫描注册,都是注册到类 DefaultListableBeanFactory 的 beanDefinitionMap 参数上,参数类型为
1
private final Map< String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>( 256);
而 DefaultListableBeanFactory 是 this 的父类 GenericApplicationContext 进行初始化的,因为在 Java 中子类初始化时会先初始化父类。
这里主要关注的就是属性
1
private final ClassPathBeanDefinitionScanner scanner;
它就是我们所说的扫描器,我们可以指定扫描某个路径 ,让其对扫描到的类进行解析。接下来就着重来看 ClassPathBeanDefinitionScanner 的扫描逻辑。
核心扫描方法ClassPathBeanDefinitionScanner#scan ClassPathBeanDefinitionScanner 源码如下:
1
2
3
4
5
6
7
8
9
10
private final BeanDefinitionRegistry registry;
public int scan ( String... basePackages) {
int beanCountAtScanStart = this . registry . getBeanDefinitionCount ();
doScan( basePackages);
if ( this . includeAnnotationConfig ) {
AnnotationConfigUtils. registerAnnotationConfigProcessors ( this . registry );
}
return ( this . registry . getBeanDefinitionCount () - beanCountAtScanStart);
}
可以看到 scan() 方法比较简单,传进来包路径作为参数,调用了 doScan() 方法来完成扫描处理,值得说明的是 Spring 源码中都是类似的命名风格,doXXX 表示具体处理什么。
ClassPathBeanDefinitionScanner 是一个扫描器,这里 registry 是一个接口 BeanDefinitionRegistry,运行的时候实际的值其实就是 DefaultListableBeanFactory。但是这里扫描器只需要完成注册 BeanDefinition 就可以了,所以没必要用 DefaultListableBeanFactory,更符合单一职责。
接下来来看 ClassPathBeanDefinitionScanner#doScan 方法的源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
protected Set< BeanDefinitionHolder> doScan ( String... basePackages) {
Assert. notEmpty ( basePackages, "At least one base package must be specified" );
Set< BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for ( String basePackage : basePackages) {
Set< BeanDefinition> candidates = findCandidateComponents( basePackage);
for ( BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this . scopeMetadataResolver . resolveScopeMetadata ( candidate);
candidate. setScope ( scopeMetadata. getScopeName ());
String beanName = this . beanNameGenerator . generateBeanName ( candidate, this . registry );
if ( candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition(( AbstractBeanDefinition) candidate, beanName);
}
if ( candidate instanceof AnnotatedBeanDefinition) {
}
if ( checkCandidate( beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder( candidate, beanName);
definitionHolder = AnnotationConfigUtils. applyScopedProxyMode ( scopeMetadata, definitionHolder, this . registry );
beanDefinitions. add ( definitionHolder);
registerBeanDefinition( definitionHolder, this . registry );
}
}
}
return beanDefinitions;
}
basePackages 即指定的扫描路径。
findCandidateComponents(basePackage) 这个方法就是最核心的扫描逻辑。
ClassPathScanningCandidateComponentProvider#findCandidateComponents :
1
2
3
4
5
6
7
public Set< BeanDefinition> findCandidateComponents ( String basePackage) {
if ( this . componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex( this . componentsIndex , basePackage);
} else {
return scanCandidateComponents( basePackage);
}
}
这里会判断我们是否有定义组件索引,来执行不同扫描逻辑。
有索引的扫描流程 这个方法会去判断this.componentsIndex 是否有值,这个就是我们配置的 Bean 索引,它加载的是 META-INF/spring.components中的信息,内容格式形如:
1
com. vitahlin . bean . xxxBean = org. springframework . stereotype . Component
配置之后,就会加载这里的 Bean 组件,不去做路径下的全部扫描。对于项目过于庞大,扫描耗费时间的情况,可以考虑这种方案。一般情况下都走默认的扫描流程。
默认的扫描流程scanCandidateComponents 接着来看默认的扫描流程
ClassPathScanningCandidateComponentProvider#scanCandidateComponents :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
private Set< BeanDefinition> scanCandidateComponents ( String basePackage) {
Set< BeanDefinition> candidates = new LinkedHashSet<>();
try {
String packageSearchPath = ResourcePatternResolver. CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage( basePackage) + '/' + this . resourcePattern ;
Resource[] resources = getResourcePatternResolver(). getResources ( packageSearchPath);
boolean traceEnabled = logger. isTraceEnabled ();
boolean debugEnabled = logger. isDebugEnabled ();
for ( Resource resource : resources) {
if ( traceEnabled) {
logger. trace ( "Scanning " + resource);
}
if ( resource. isReadable ()) {
try {
MetadataReader metadataReader = getMetadataReaderFactory(). getMetadataReader ( resource);
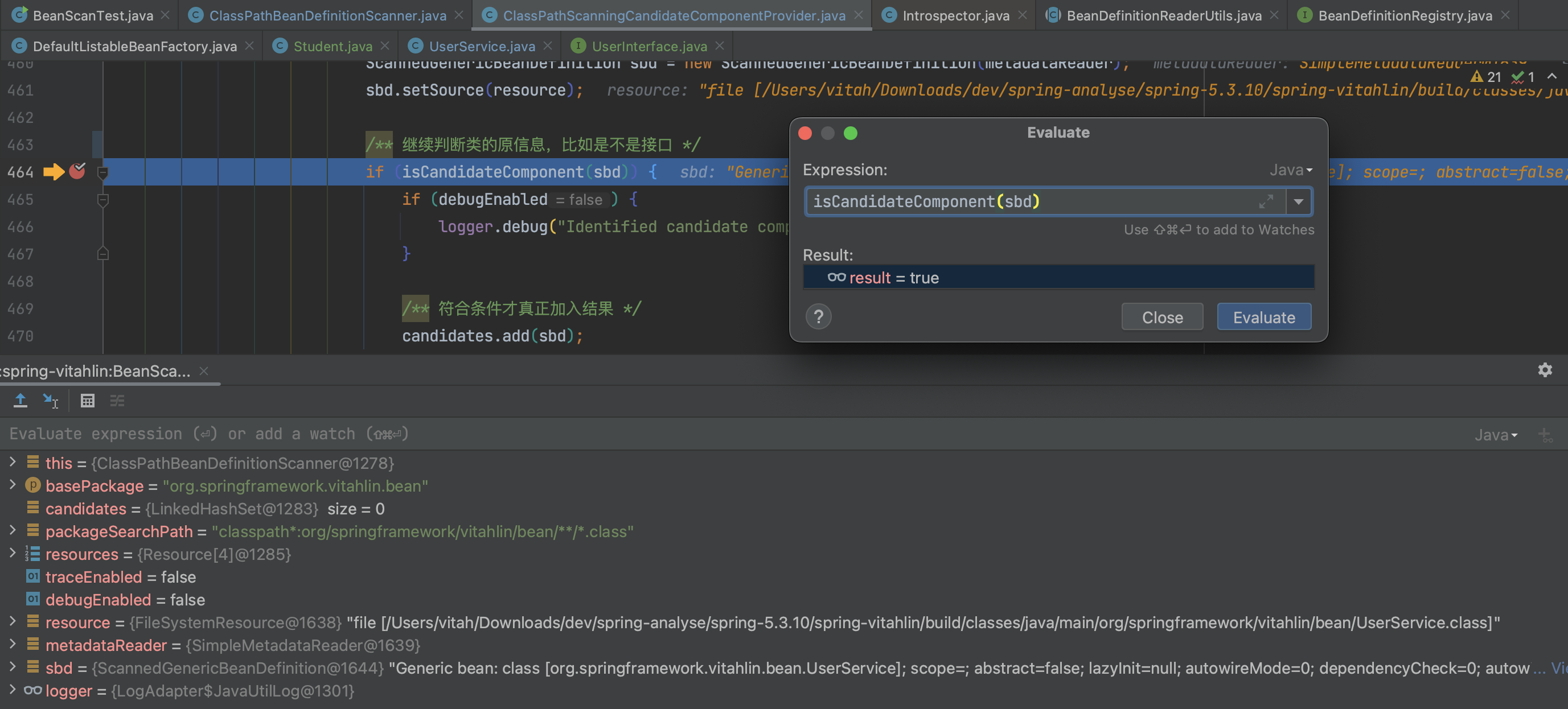
if ( isCandidateComponent( metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition( metadataReader);
sbd. setSource ( resource);
if ( isCandidateComponent( sbd)) {
if ( debugEnabled) {
logger. debug ( "Identified candidate component class: " + resource);
}
candidates. add ( sbd);
} else {
if ( debugEnabled) {
logger. debug ( "Ignored because not a concrete top-level class: " + resource);
}
}
} else {
if ( traceEnabled) {
logger. trace ( "Ignored because not matching any filter: " + resource);
}
}
} catch ( Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
}
} else {
if ( traceEnabled) {
logger. trace ( "Ignored because not readable: " + resource);
}
}
}
} catch ( IOException ex) {
throw new BeanDefinitionStoreException( "I/O failure during classpath scanning" , ex);
}
return candidates;
}
其中 scanCandidateComponents 方法就是扫描的核心流程,
构建扫描路径 这里,传入包路径就是字符串,先构造对应的包路径:
1
2
String packageSearchPath = ResourcePatternResolver. CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage( basePackage) + '/' + this . resourcePattern ;
这里可以加个 print 语句来查看最终的路径是什么:
1
2
3
4
String packageSearchPath = ResourcePatternResolver. CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage( basePackage) + '/' + this . resourcePattern ;
System. out . println ( "basePackage:" + basePackage);
System. out . println ( "packageSearchPath:" + packageSearchPath);
执行结果:
1
2
basePackage:org.springframework.vitahlin.bean
packageSearchPath:classpath*:org/springframework/vitahlin/bean/**/*.class
这里的处理逻辑是包名前面加上 classpath*: 前缀,后面加上 **/*.class,同时把包名中的 . 替换成 / ,得到搜索路径,最终要匹配查找的是包路径下的 class 文件 ,包下面可能还有其他文件,但是这里就不管了。
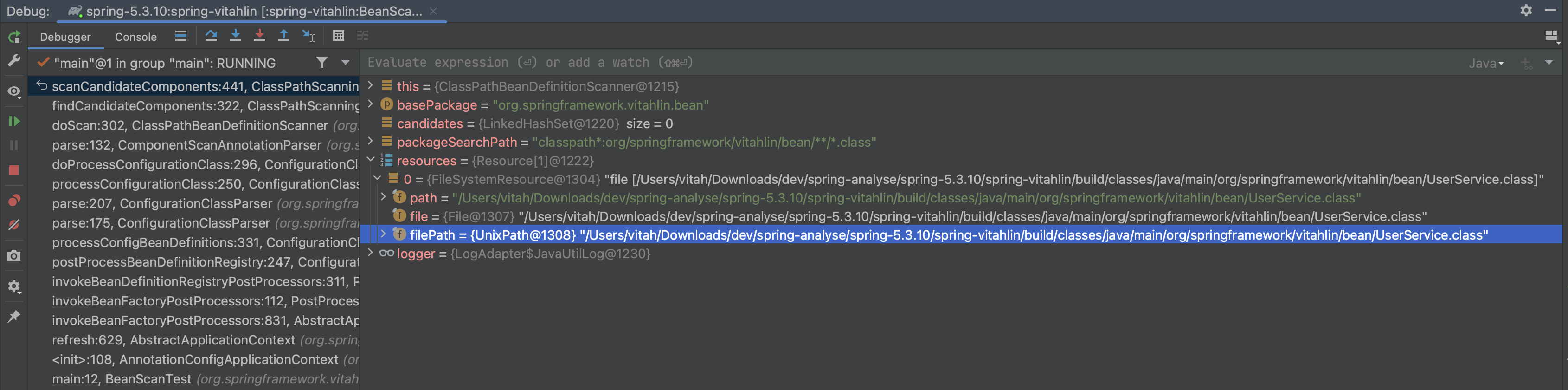
获取包路径下的资源 拿到对应的包路径后,Spring 就用本身的 resource 工具去获取该路径下的资源文件,找出来的其实就是 class 文件的 file 对象。调试信息如下:Rescource 就是一个个 class 文件的文件对象 ,接下来就是遍历获取到的 Resource 资源,逐个处理了。
获取类对应的元数据 getMetadataReader 则是根据 Resource 获取类对应的元数据。
什么是元数据?
Metadata is simply data about data. It means it is a description and context of the data. It helps to organize, find and understand data。
上面介绍的大概意思是:元数据是关于数据的数据,元数据是数据的描述和上下文,它有助于组织,查找,理解和使用数据。
Spring 对 MetadataReader 的描述为:
Simple facade for accessing class metadata,as read by an ASM.
大意是通过 ASM 读取 class IO 流资源组装访问元数据的门面接口。反正,这里通过 MetadataReader 我们就能拿到类的信息,比如类的名字,类的注解信息等。这里使用了 ASM 技术。
MetadataReader表示类的元数据读取器,主要包含了一个AnnotationMetadata,功能有:
获取类的名字; 获取父类的名字; 获取所实现的所有接口名; 获取所有内部类的名字; 判断是不是抽象类; 判断是不是接口; 判断是不是一个注解; 获取拥有某个注解的方法集合; 获取类上添加的所有注解信息; 获取类上添加的所有注解类型集合; 判断类是否有@Component注解 拿到类的元信息后,就需要判断这个类是不是一个Bean 。我们可能定义了一个类,但是这个类并不是我们需要的 Bean,那么这里是怎么处理的呢?
@Component is a generic stereotype for any Spring-managed component. @Repository, @Service, and @Controller are specializations of @Component
大概意思是 @Component 是任何 Spring 管理的组件的通用原型。@Repository 、@Service 和@Controller 是派生自 @Component 。
ClassPathScanningCandidateComponentProvider#isCandidateComponent 源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
protected boolean isCandidateComponent ( MetadataReader metadataReader) throws IOException {
/** 类和某个类排除过滤器匹配,就忽略 */
for ( TypeFilter tf : this . excludeFilters ) {
if ( tf. match ( metadataReader, getMetadataReaderFactory())) {
return false ;
}
}
/**
* 符合includeFilter的会进行匹配,通过了才是Bean,这里先判断是否有@Component注解。
* spring扫描器初始化的时候会注册一个默认的包含过滤器,即类上是否有Component注解的包含过滤器
*/
for ( TypeFilter tf : this . includeFilters ) {
if ( tf. match ( metadataReader, getMetadataReaderFactory())) {
/** 再判断@Condition条件注解 */
return isConditionMatch( metadataReader);
}
}
return false ;
}
这里并不是直接判断类上是否存在 @Component 注解,而是去判断类的排除过滤器和包含过滤器 :
首先我这个类和任意一个排除过滤器匹配了,那么我就排除这个类; 如果排除过滤器符合,那么继续判断包含过滤器。即如果要成为一个 bean,一定要符合某个包含过滤器才行。 那么这里为什么是通过判断包含过滤器而不是判断是否有注解 @Component ?
实际上,在 Spring 的 scanner 初始化的时候会注册一个默认的包含过滤器 ,我们回过头来看 ClassPathBeanDefinitionScanner 初始化的代码,ClassPathBeanDefinitionScanner#ClassPathBeanDefinitionScanner :
1
2
3
4
5
6
7
8
9
10
11
public ClassPathBeanDefinitionScanner ( BeanDefinitionRegistry registry, boolean useDefaultFilters,
Environment environment, @Nullable ResourceLoader resourceLoader) {
Assert. notNull ( registry, "BeanDefinitionRegistry must not be null" );
this . registry = registry;
/*** 注册默认的包含过滤器 */
if ( useDefaultFilters) {
registerDefaultFilters();
}
setEnvironment( environment);
setResourceLoader( resourceLoader);
}
继续跟进方法 registerDefaultFilters ,ClassPathScanningCandidateComponentProvider#registerDefaultFilters:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
protected void registerDefaultFilters () {
// 添加默认的Component注解包含过滤器
this . includeFilters . add ( new AnnotationTypeFilter( Component. class ));
ClassLoader cl = ClassPathScanningCandidateComponentProvider. class . getClassLoader ();
try {
this . includeFilters . add ( new AnnotationTypeFilter(
(( Class<? extends Annotation>) ClassUtils. forName ( "javax.annotation.ManagedBean" , cl)), false ));
logger. trace ( "JSR-250 'javax.annotation.ManagedBean' found and supported for component scanning" );
} catch ( ClassNotFoundException ex) {
// JSR-250 1.1 API (as included in Java EE 6) not available - simply skip.
}
try {
this . includeFilters . add ( new AnnotationTypeFilter(
(( Class<? extends Annotation>) ClassUtils. forName ( "javax.inject.Named" , cl)), false ));
logger. trace ( "JSR-330 'javax.inject.Named' annotation found and supported for component scanning" );
} catch ( ClassNotFoundException ex) {
// JSR-330 API not available - simply skip.
}
}
可以看到方法的第一行即添加了默认的包含过滤器 。 我们可以新建一个非bean的类来测试下。
非Bean类测试用例 新建一个类Student,但是不加 @Component 注解:
1
2
3
4
5
6
7
package org.springframework.vitahlin.bean;
public class Student {
public void hello () {
System. out . println ( "hello Student" );
}
}
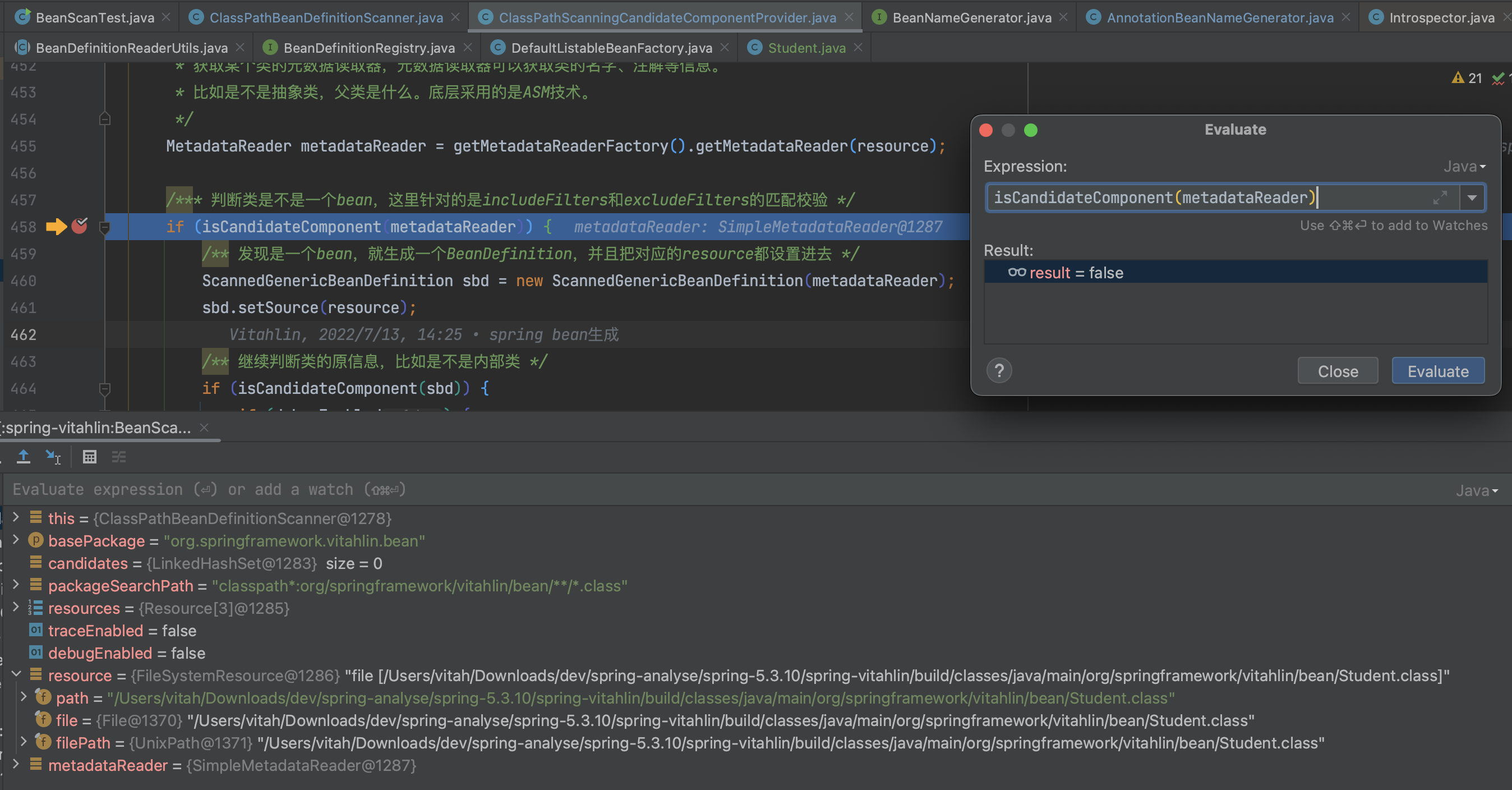
然后开始断点:for 循环处理的是 Student.class 这个类,然后右键 isCandidateComponent -> Evuluate Expression ,得到的结果为 false,即 Spring 不认为 Student 是一个 bean。
所以这里判断包含过滤器即判断类上是否有 @Component 注解,如果有那么就是匹配的,即是一个 Bean。
条件匹配 通过 filter 判断是否有 @Component 注解后,还需要继续判断当前类是否满足条件注解,即 isConditionMatch(metadataReader); 这个方法,这里最终调用的方法是 ConditionEvaluator#shouldSkip ,如图所示:image.png
这里不细讲判断条件注解的源码,我们只需要大概了解流程如下:
类如果没有 ``@Conditional` 直接,返回 false,表示不跳过 类有@Conditional 注解,获取类上条件注解的类,执行判定 构造 ScannedGenericBeanDefinition 上一步判断完成后,确认类是一个Bean,就会根据元数据开始构造一个 ScannedGenericBeanDefinition 。
1
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition( metadataReader);
跟进 ScannedGenericBeanDefinition 的构造函数ScannedGenericBeanDefinition#ScannedGenericBeanDefinition :
1
2
3
4
5
6
7
public ScannedGenericBeanDefinition ( MetadataReader metadataReader) {
Assert. notNull ( metadataReader, "MetadataReader must not be null" );
this . metadata = metadataReader. getAnnotationMetadata ();
/*** 一开始只是把class name复制给属性,并没有真正的加载类 */
setBeanClassName( this . metadata . getClassName ());
setResource( metadataReader. getResource ());
}
AbstractBeanDefinition#setBeanClassName 方法处理:
1
2
3
4
5
6
7
8
9
10
public abstract class AbstractBeanDefinition extends BeanMetadataAttributeAccessor
implements BeanDefinition, Cloneable {
@Nullable
private volatile Object beanClass;
@Override
public void setBeanClassName ( @Nullable String beanClassName) {
this . beanClass = beanClassName;
}
}
注意这里,一开始我们只是把这个类的名字赋给了BeanDefinition 。
这里的 beanClass 属性为什么是 Object 类型?
因为在这里,一开始我们只是把 bean 的名字赋给了它,当我需要这个类的时候,就需要对类进行实例化,实例化后我就能把实例化后的类型赋给 beanClass 属性,覆盖掉原先 String 类型的 BeanName。所以这个 beanClass 分两种情况:
一开始的时候是类的名字 后面实例化后一个类的对象。 判断扫描到的类是不是独立的 1
2
3
4
5
6
if ( isCandidateComponent( sbd)) {
if ( debugEnabled) {
logger. debug ( "Identified candidate component class: " + resource);
}
candidates. add ( sbd);
}
构造完 ScannedGenericBeanDefinition 后,这里还会继续判断 Bean 的类型,比如是不是抽象类。这里涉及到一个概念,类是否是独立的 。
源码注释中是这么说的:
Determine whether the underlying class is independent, i.e. whether it is a top-level class or a nested class (static inner class) that can be constructed independently of an enclosing class.
具体来看方法 ClassPathScanningCandidateComponentProvider#isCandidateComponent:
1
2
3
4
5
6
7
8
9
10
11
protected boolean isCandidateComponent ( AnnotatedBeanDefinition beanDefinition) {
AnnotationMetadata metadata = beanDefinition. getMetadata ();
/**
* isIndependent当前类是否顶级类或者嵌套类
* isConcrete不是接口,不是抽象类,就返回true
* 如果bean是抽象类并且添加类@Lookup注解,那么可以注入
*/
return ( metadata. isIndependent () && ( metadata. isConcrete () ||
// 确实是抽象类,但是有Lookup注解
( metadata. isAbstract () && metadata. hasAnnotatedMethods ( Lookup. class . getName ()))));
}
测试用例 这里涉及到了独立类的概念,新建 UserInterface 接口类:
1
2
3
4
5
6
7
8
package org.springframework.vitahlin.bean;
import org.springframework.stereotype.Service;
@Service
public interface UserInterface {
void sayHello ();
}
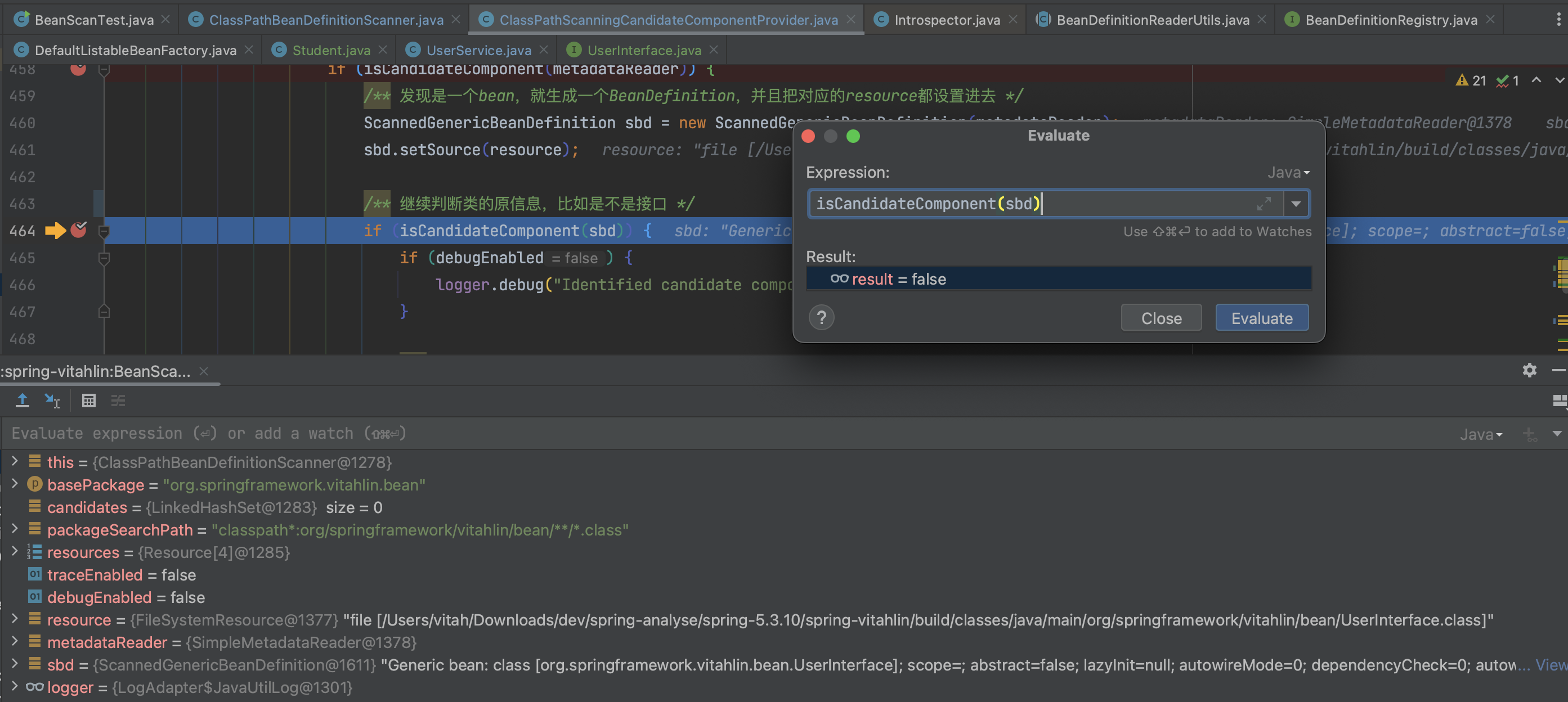
然后断点查看 isCandidateComponent 的执行结果,如下:
虽然 UserInterface 加了 @Service 注解,但是它并不是独立的将会被过滤。这个方法就是用来过滤诸如内部类、抽象类等,即不依赖其他类也能正常被构建。因为后续扫描完成,有一个很重要的步骤是实例化,而那些非静态的内部类、接口、抽象类是不能被实例化的,故这里需排除在外。
反之,对 UserService 的判定:
可以看到,结果为 true 。
判定类是可以注册 BeanDefinition 的,就将生成的 ScannedGenericBeanDefinition 加入到 一开始定义的 BeanDefinition 集合Set<BeanDefinition> candidates 中,那么这里就完成了类的扫描,接下来就就开始逐个遍历扫描得到的 BeanDefinition 集合,根据 BeanDefinition 生成对应的 Bean。
Bean的scope处理 1
2
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition( metadataReader);
sbd. setSource ( resource);
这里是处理 BeanDefinition的scope属性,默认是单例属性。
BeanDefinition名字生成 处理完 BeanDefinition 属性后,开始处理 Bean 的名字:
1
String beanName = this . beanNameGenerator . generateBeanName ( candidate, this . registry );
这行代码,处理了 bean 名字的生成,这里会调用 AnnotationBeanNameGenerator#generateBeanName,根据AnnotationBeanNameGenerator#generateBeanName 源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
@Override
public String generateBeanName ( BeanDefinition definition, BeanDefinitionRegistry registry) {
if ( definition instanceof AnnotatedBeanDefinition) {
String beanName = determineBeanNameFromAnnotation(( AnnotatedBeanDefinition) definition);
if ( StringUtils. hasText ( beanName)) {
// Explicit bean name found.
return beanName;
}
}
// Fallback: generate a unique default bean name.
// 没有找到@Component注解自定义的value值,则生成一个
return buildDefaultBeanName( definition, registry);
}
这里分为2部分:
先是判断我们是不是在注解上自定义了 Bean 的名字 如果没有则根据默认规则生成 Bean 名字 判断注解是不是定义了Bean名字 AnnotationBeanNameGenerator#determineBeanNameFromAnnotation 方法源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
@Nullable
protected String determineBeanNameFromAnnotation ( AnnotatedBeanDefinition annotatedDef) {
AnnotationMetadata amd = annotatedDef. getMetadata ();
Set< String> types = amd. getAnnotationTypes ();
String beanName = null ;
for ( String type : types) {
AnnotationAttributes attributes = AnnotationConfigUtils. attributesFor ( amd, type);
if ( attributes != null ) {
Set< String> metaTypes = this . metaAnnotationTypesCache . computeIfAbsent ( type, key -> {
Set< String> result = amd. getMetaAnnotationTypes ( key);
return ( result. isEmpty () ? Collections. emptySet () : result);
});
if ( isStereotypeWithNameValue( type, metaTypes, attributes)) {
/*** 如果是@Component注解,查看是否有自定义value注解,有的话返回value的值,没有返回null */
Object value = attributes. get ( "value" );
if ( value instanceof String) {
String strVal = ( String) value;
if ( StringUtils. hasLength ( strVal)) {
if ( beanName != null && ! strVal. equals ( beanName)) {
throw new IllegalStateException( "Stereotype annotations suggest inconsistent " +
"component names: '" + beanName + "' versus '" + strVal + "'" );
}
beanName = strVal;
}
}
}
}
}
return beanName;
}
获取当前类上的注解,然后 isStereotypeWithNameValue 方法判断是否存在注解 @Component,如果有的话获取它的 value 值,如果没有注解或者没有 value 值,则返回 null。
生成默认的Bean名称 如果没有找到我们自定义的 beanName,就需要生成一个默认的 beanName,AnnotationBeanNameGenerator#buildDefaultBeanName :
1
2
3
4
5
6
7
protected String buildDefaultBeanName ( BeanDefinition definition) {
String beanClassName = definition. getBeanClassName ();
Assert. state ( beanClassName != null , "No bean class name set" );
String shortClassName = ClassUtils. getShortName ( beanClassName);
/*** 在这里,如果Bean名称的头两个字符都是大写,那么Bean名称就直接是当前的类名,不然取第一个字母小写的类名 */
return Introspector. decapitalize ( shortClassName);
}
ClassUtils.getShortName 就是根据 Bean 的全路径名字获取类名,比如 com.vitahlin.service.HelloSerivce 得到的 shortClassName 就是 HelloService。
这里,重点来看Introspector#decapitalize :
1
2
3
4
5
6
7
8
9
10
11
12
public static String decapitalize ( String name) {
if ( name == null || name. length () == 0) {
return name;
}
if ( name. length () > 1 && Character. isUpperCase ( name. charAt ( 1)) &&
Character. isUpperCase ( name. charAt ( 0))){
return name;
}
char chars[] = name. toCharArray ();
chars[ 0] = Character. toLowerCase ( chars[ 0]);
return new String( chars);
}
会判断类名字的第一个字符和第二个字符,如果前2个字符全部大写的话,那么直接返回类名;否则将返回首字符小写的类名字。 比如类,AbcService 它的bean名字就是 abcService ,类 ABcService 它的bean名字则是 ABcService 。
这里总结下 bean 名字的生成规则:
判断该类上的注解 @Component 的 value 值
若该值存在, 则返回 若该值不存在,则调用方法生成默认名字
- 若类名前两个字符都是大写字符则直接返回,
- 否则将第一个字符小写返回 Bean的默认值处理 1
2
3
4
/*** 如果扫描得到的Bean不是spring的注解Bean,则为Bean设置默认值,设置Bean的自动注入依赖装配属性等 */
if ( candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition(( AbstractBeanDefinition) candidate, beanName);
}
主要处理一些 bean 的默认值,比如我们没有设置懒加载选项,就默认设为非懒加载。
判断Bean是否重复 接下来,方法 checkCandidate(beanName, candidate) 会判断类是否重复,最终调用的是ClassPathBeanDefinitionScanner#checkCandidate:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
protected boolean checkCandidate ( String beanName, BeanDefinition beanDefinition) throws IllegalStateException {
/*** 判断容器里面是不是已经存在这个beanName */
if (! this . registry . containsBeanDefinition ( beanName)) {
return true ;
}
BeanDefinition existingDef = this . registry . getBeanDefinition ( beanName);
/*** 这里先不分析,后续分析 */
BeanDefinition originatingDef = existingDef. getOriginatingBeanDefinition ();
if ( originatingDef != null ) {
existingDef = originatingDef;
}
if ( isCompatible( beanDefinition, existingDef)) {
return false ;
}
throw new ConflictingBeanDefinitionException( "Annotation-specified bean name '" + beanName +
"' for bean class [" + beanDefinition. getBeanClassName () + "] conflicts with existing, " +
"non-compatible bean definition of same name and class [" + existingDef. getBeanClassName () + "]" );
}
方法 isCompatible(beanDefinition, existingDef) 判断已经存在的 Bean 和我现在要生成的是不是兼容, 如果兼容不抛异常,但是返回 false,也不会重新注册 Bean 。
ClassPathBeanDefinitionScanner#isCompatible :
1
2
3
4
5
protected boolean isCompatible ( BeanDefinition newDefinition, BeanDefinition existingDefinition) {
return (!( existingDefinition instanceof ScannedGenericBeanDefinition) || // explicitly registered overriding bean
( newDefinition. getSource () != null && newDefinition. getSource (). equals ( existingDefinition. getSource ())) || // scanned same file twice
. equals ( existingDefinition)); // scanned equivalent class twice
}
这里其实就是判断两个 BeanDefinition 的 resource 是否一致。一个类会被扫描多次,导致两个不同的 BeanDefinition 实际上是同一个类。这时候如果已经扫描过,那么不重复注册直接跳过。
如果不是兼容的类,但是 BeanName 一样就会抛出我们平常比较常见的异常内容。
不重复就将扫描得到的 Bean 添加到列表中。到这里就完成了整个 Bean 扫描的逻辑,接下来就可以根据得到的 BeanDefinition 集合进行初始化了。
向容器注册扫描得到的BeanDefinition 1
registerBeanDefinition( definitionHolder, this . registry );
这个方法调用的是 BeanDefinitionReaderUtils#registerBeanDefinition :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public static void registerBeanDefinition (
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// Register bean definition under primary name.
= definitionHolder. getBeanName ();
// 注册到bean工厂
. registerBeanDefinition ( beanName, definitionHolder. getBeanDefinition ());
// Register aliases for bean name, if any.
[] aliases = definitionHolder. getAliases ();
if ( aliases != null ) {
for ( String alias : aliases) {
registry. registerAlias ( beanName, alias);
}
}
}
看其中的 registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition()),它是一个接口 BeanDefinitionRegistry,实际上的实现方法是DefaultListableBeanFactory#registerBeanDefinition:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
@Override
public void registerBeanDefinition ( String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
Assert. hasText ( beanName, "Bean name must not be empty" );
Assert. notNull ( beanDefinition, "BeanDefinition must not be null" );
if ( beanDefinition instanceof AbstractBeanDefinition) {
try {
(( AbstractBeanDefinition) beanDefinition). validate ();
} catch ( BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException( beanDefinition. getResourceDescription (), beanName,
"Validation of bean definition failed" , ex);
}
}
BeanDefinition existingDefinition = this . beanDefinitionMap . get ( beanName);
if ( existingDefinition != null ) {
if (! isAllowBeanDefinitionOverriding()) {
throw new BeanDefinitionOverrideException( beanName, beanDefinition, existingDefinition);
} else if ( existingDefinition. getRole () < beanDefinition. getRole ()) {
// e.g. was ROLE_APPLICATION, now overriding with ROLE_SUPPORT or ROLE_INFRASTRUCTURE
if ( logger. isInfoEnabled ()) {
logger. info ( "Overriding user-defined bean definition for bean '" + beanName +
"' with a framework-generated bean definition: replacing [" +
existingDefinition + "] with [" + beanDefinition + "]" );
}
} else if (! beanDefinition. equals ( existingDefinition)) {
if ( logger. isDebugEnabled ()) {
logger. debug ( "Overriding bean definition for bean '" + beanName +
"' with a different definition: replacing [" + existingDefinition +
"] with [" + beanDefinition + "]" );
}
} else {
if ( logger. isTraceEnabled ()) {
logger. trace ( "Overriding bean definition for bean '" + beanName +
"' with an equivalent definition: replacing [" + existingDefinition +
"] with [" + beanDefinition + "]" );
}
}
// 这里把beanDefinition放到beanMap里面
this . beanDefinitionMap . put ( beanName, beanDefinition);
} else {
if ( hasBeanCreationStarted()) {
// Cannot modify startup-time collection elements anymore (for stable iteration)
synchronized ( this . beanDefinitionMap ) {
this . beanDefinitionMap . put ( beanName, beanDefinition);
List< String> updatedDefinitions = new ArrayList<>( this . beanDefinitionNames . size () + 1);
updatedDefinitions. addAll ( this . beanDefinitionNames );
updatedDefinitions. add ( beanName);
this . beanDefinitionNames = updatedDefinitions;
removeManualSingletonName( beanName);
}
} else {
// Still in startup registration phase
this . beanDefinitionMap . put ( beanName, beanDefinition);
this . beanDefinitionNames . add ( beanName);
removeManualSingletonName( beanName);
}
this . frozenBeanDefinitionNames = null ;
}
if ( existingDefinition != null || containsSingleton( beanName)) {
resetBeanDefinition( beanName);
} else if ( isConfigurationFrozen()) {
clearByTypeCache();
}
}
其中
this.beanDefinitionMap.put(beanName, beanDefinition)这行就是把扫描得到的 BeanDefinition 注册到集合中this.beanDefinitionNames.add(beanName);这里还会保存一份 beanName 的集合。至此就完成了Bean 的扫描整个流程,容器中已经有了对应的 BeanDefinition,后续就可以根据 BeanDefinition 集合进行 bean 的实例化。
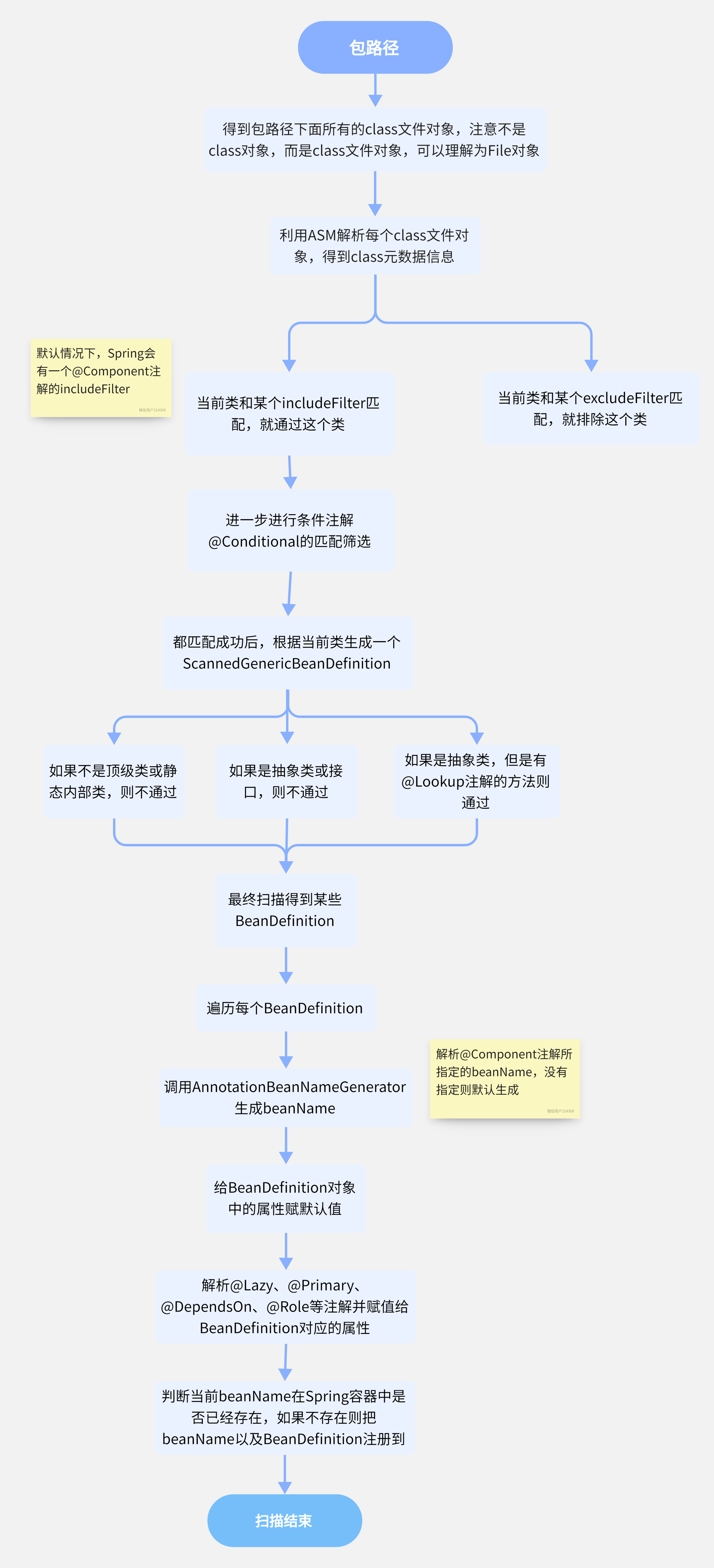
结语 大概总结 Bean 的扫描流程如下:
首先,通过 ResourcePatternResolver 获得指定包路径下的所有.class文件(Spring源码中将此文件包装成了Resource 对象); 遍历每个 Resource 对象; 利用 MetadataReaderFactory 解析 Resource 对象得到 MetadataReader(在Spring 源码中 MetadataReaderFactory 具体的实现类为CachingMetadataReaderFactory,MetadataReader 的具体实现类为SimpleMetadataReader)。值得注意的是,CachingMetadataReaderFactory解析某个 .class 文件得到 MetadataReader 对象是利用的ASM 技术,并没有加载这个类到JVM。并且,最终得到的 ScannedGenericBeanDefinition 对象,beanClass属性存储的是当前类的名字,而不是class对象 。 利用 MetadataReader 进行 excludeFilters 和 includeFilters,以及条件注解@Conditional 的筛选; 筛选通过后,基于 metadataReader 生成 ScannedGenericBeanDefinition 再基于 metadataReader 判断是不是对应的类是不是接口或抽象类 如果筛选通过,那么就表示扫描到了一个Bean,将ScannedGenericBeanDefinition 加入结果集 BeanDefinition集合生成过程的流程图如下:Spring Bean扫描.png