

关注问题
- 什么是 Buffer Pool
- SQL 执行流程是怎样的
- Buffer Pool 在数据库中如何发挥作用
- 随机读写和顺序读写的区别是什么
Buffer Pool 是什么
在使用 MySQL 时,比如简单的 select * from table 语句,具体查询数据其实是在存储引擎实现的,MySQL 的数据是放在磁盘里的,如果每次查询都直接从磁盘里面查询,会很影响性能,所以一定是先把数据从磁盘中取出,然后放在内存中,下次查询直接从内存中取。
但是一台机器中往往不是只有 MySQL 一个进程在运行,很多个进程都需要使用内存,所以 MySQL 会有一个专门的区域来处理这些数据,Buffer Pool(缓冲池)是数据库管理系统(DBMS)中的一块内存区域,用于缓存磁盘上的数据页,以提高数据访问性能,减少磁盘 I/O 操作。是 MySQL 一个非常关键的核心组件。
SQL 执行流程图
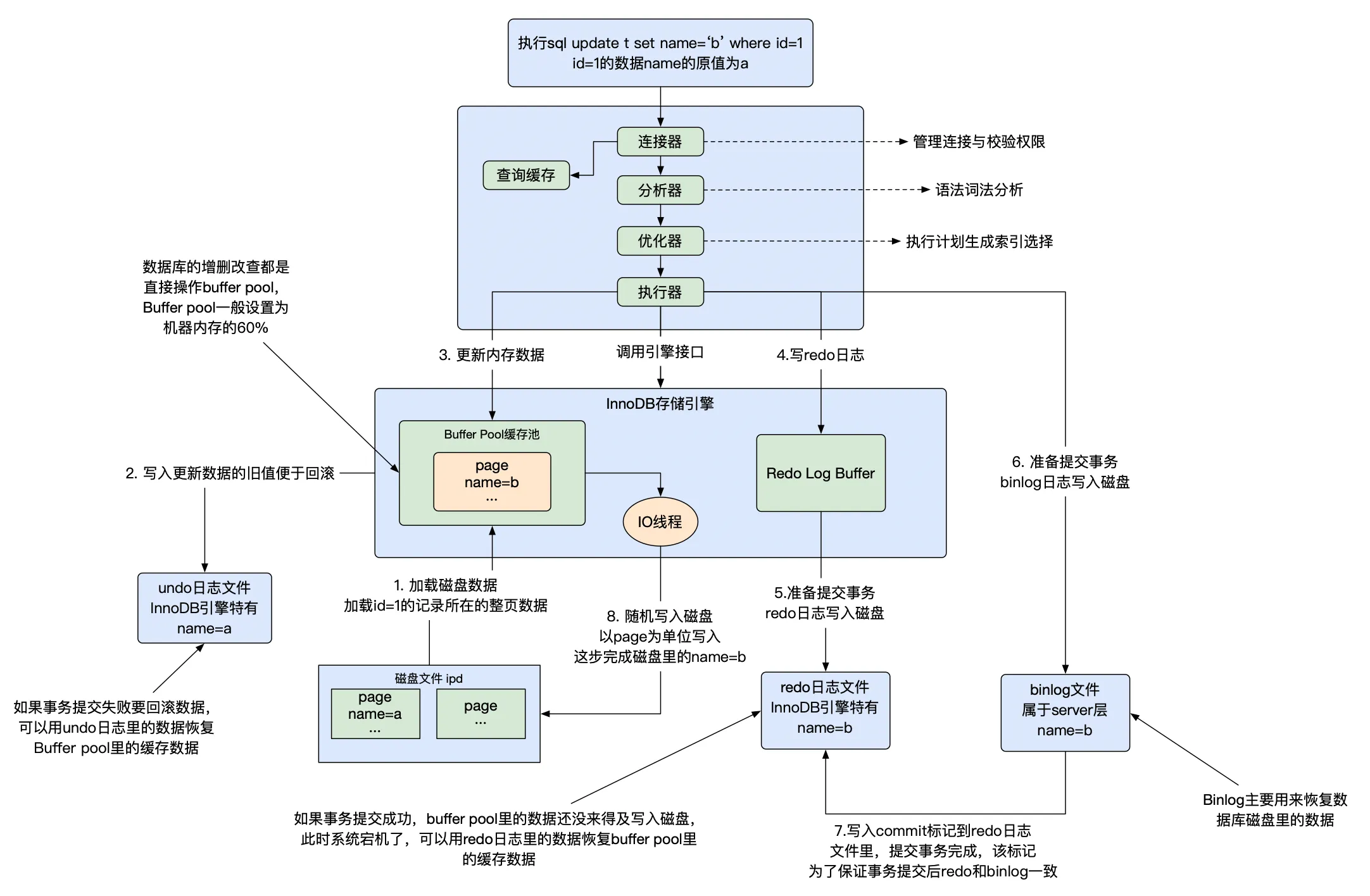
其中,当我们客户端执行 commit 提交事务的操作的时候,数据并不是真正写入到磁盘上,MySQL 内部会执行上述中的 5-6-7 步骤,步骤 7 成功后客户端就收到了当前事务执行成功的通知。这时候如果宕机了,启动后 MySQL 根据 redo-log 的内容恢复 buffer pool 的数据。
上述操作中,只有步骤-1 查询的时候可能是对磁盘进行随机读写,其他日志的写入都是不涉及到删除的,而是顺序的写入。
Buffer Pool 在数据库中的作用
- 缓存数据页:数据库读取数据时,先在 Buffer Pool 查找,如果有(命中),直接返回,避免磁盘读取。
- 减少磁盘 I/O:磁盘 I/O 速度远低于内存,缓冲池可以最大化利用内存,减少对磁盘的依赖。
- 提高查询性能:Buffer Pool 让常用数据保持在内存中,加快查询速度。
- 写入优化:修改的数据页不会立即写入磁盘,而是先存入缓冲池,等合适时机(如 Checkpoint 或 LRU 机制)批量写入,提高效率。
那么为什么要设计一套复杂的机制来执行 SQL 而不是直接更新磁盘数据? 我们就需要来了解什么是随机读写和顺序读写。
随机读写和顺序读写
随机和顺序读写,是存储器的两种输入输出方式。存储的数据在磁盘中占据空间,对于一个新磁盘,操作系统会将数据文件依次写入磁盘,当有些数据被删除时,就会空出该数据原来占有的存储空间,时间长了,不断的写入、删除数据,就会产生很多零零散散的存储空间,就会造成一个较大的数据文件放在许多不连续的存贮空间上,读写些这部分数据时,就是随机读写,磁头要不断的调整磁道的位置,以在不同位置上的读写数据,相对于连续空间上的顺序读写,要耗时很多。
顺序读写 :指的是本次 I/O 给出的初始扇区地址和上一次 I/O 的结束扇区地址是完全连续或者相隔不多的。反之,如果相差很大,则算作一次随机 I/O。
而发生随机 I/O 可能是因为磁盘碎片导致磁盘空间不连续,或者当前 block 空间小于文件大小导致的。
连续 I/O 比随机 I/O 效率高的原因是:在做连续 I/O 的时候,磁头几乎不用换道,或者换道的时间很短;而对于随机 I/O,如果这个 I/O 很多的话,会导致磁头不停地换道,造成效率的极大降低。
对于磁盘的读写分为两种模式,顺序 IO 和随机 IO。随机 IO 存在一个寻址的过程,所以效率比较低。而顺序 IO,相当于有一个物理索引,在读取的时候不需要寻找地址,效率很高。
MySQL 如果来一个请求查询数据,就直接对磁盘文件进行随机读写,然后更新磁盘文件里的数据性能可能相当差。磁盘随机读写的性能是非常差的,所以直接更新磁盘文件是不能让数据库抗住很高并发的。
MySQL 这套机制看起来复杂,但它可以保证每个更新请求都是更新内存 BufferPool,然后顺序写日志文件,同时还能保证各种异常情况下的数据一致性。更新内存的性能是极高的,然后顺序写磁盘上的日志文件的性能也是非常高的,要远高于随机读写磁盘文件。
在日常项目开发中在设计存储时,一定要考虑顺序和随机,优化其性能达到最高。例如,当前大多数数据库使用的都是传统的机械磁盘,因此,整个系统设计要尽可能顺序 I/O,避免昂贵的寻道时间和旋转延迟的开销。