

如何保证消息不丢失
哪些环节可能丢消息
MQ 中通用场景图:
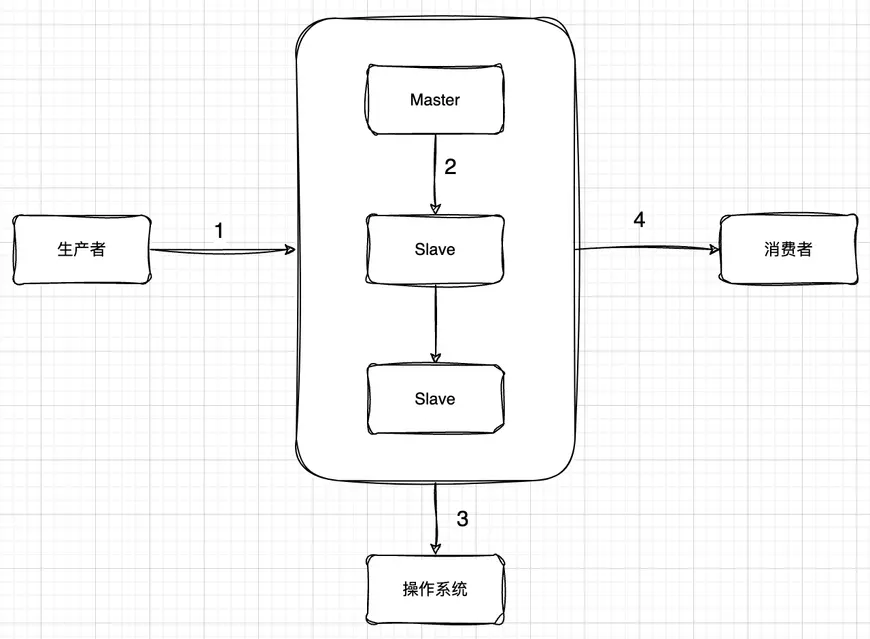
其中步骤 1、2、4 都是跨网络的都可能失败。
然后关于 3 这个环节,通常 MQ 存盘时都会先写入操作系统的缓存 page cache 中,然后再由操作系统异步的将消息写入硬盘。这个中间有个时间差,就可能会造成消息丢失。如果服务挂了,缓存中还没有来得及写入硬盘的消息就会丢失。这也是任何用户态的应用程序无法避免的。 对于任何 MQ 产品,都应该从这四个方面来考虑数据的安全性。
RabbitMQ 消息零丢失方案
1. 生产者保证消息正确发送到 RibbitMQ
对于单个数据,可以使用生产者确认机制。通过多次确认的方式,保证生产者的消息能够正确的发送到 RabbitMQ 中。
RabbitMQ 的生产者确认机制分为同步确认和异步确认。
-
同步确认主要是通过在生产者端使用
Channel.waitForConfirmsOrDie()指定一个等待确认的完成时间。 -
异步确认机制则是通过
channel.addConfirmListener(ConfirmCallback var1, ConfirmCallback var2)在生产者端注入两个回调确认函数。第一个函数是在生产者消息发送成功时调用,第二个函数则是生产者消息发送失败时调用。两个函数需要通过 sequenceNumber 自行完成消息的前后对应。sequenceNumber 的生成方式需要通过 channel 的序列获取。int sequenceNumber = channel.getNextPublishSeqNo()
当前版本的 RabbitMQ,可以在 Producer 中添加一个 ReturnListener,监听那些成功发到 Exchange,但是却没有路由到 Queue 的消息。如果不想将这些消息返回给 Producer,就可以在 Exchange 中,也可以声明一个 alternate-exchange 参数,将这些无法正常路由的消息转发到指定的备份 Exchange 上。
如果发送批量消息,在 RabbitMQ 中,另外还有一种手动事务的方式,可以保证消息正确发送。
手动事务机制主要有几个关键的方法:
channel.txSelect()开启事务;channel.txCommit()提交事务;channel.txRollback()回滚事务。
用这几个方法来进行事务管理。但是这种方式需要手动控制事务逻辑,并且手动事务会对 channel 产生阻塞,造成吞吐量下降。
2. RabbitMQ 消息存盘不丢消息
这个在 RabbitMQ 中比较好处理,对于 Classic 经典队列,直接将队列声明成为持久化队列即可。而新增的 Quorum 队列和 Stream 队列,都是明显的持久化队列,能更好的保证服务端消息不会丢失。
3. RabbitMQ 主从消息同步时不丢消息
这涉及到 RabbitMQ 的集群架构。首先他的普通集群模式,消息是分散存储的,不会主动进行消息同步了,是有可能丢失消息的。而镜像模式集群,数据会主动在集群各个节点当中同步,这时丢失消息的概率不会太
另外,启用 Federation 联邦机制,给包含重要消息的队列建立一个远端备份,也是一个不错的选择。
4. 消费者不丢失消息
RabbitMQ 在消费消息时可以指定是自动应答,还是手动应答。
如果是自动应答模式,消费者会在完成业务处理后自动进行应答,而如果消费者的业务逻辑抛出异常,RabbitMQ 会将消息进行重试,这样是不会丢失消息的,但是有可能会造成消息一直重复消费。
将 RabbitMQ 的应答模式设定为手动应答可以提高消息消费的可靠性。
如何保证消息幂等
当消费者消费消息处理业务逻辑时,如果抛出异常,或者不向 RabbitMQ 返回响应,默认情况下,RabbitMQ 会无限次数的重复进行消息消费。
处理幂等问题,首先要设定 RabbitMQ 的重试次数。在 SpringBoot 集成 RabbitMQ 时,可以在配置文件中指定 spring.rabbitmq.listener.simple.retry 开头的一系列属性,来制定重试策略。
然后,需要在业务上处理幂等问题。处理幂等问题的关键是要给每个消息一个唯一的标识。
如何保证消息顺序
在 RabbitMQ 当中,针对消息顺序的设计其实是比较弱的。唯一比较好的策略就是单队列+单消息推送。即一组有序消息,只发到一个队列中,利用队列的 FIFO 特性保证消息在队列内顺序不会乱。但是,显然,这是以极度消耗性能作为代价的,在实际适应过程中,应该尽量避免这种场景。 然后在消费者进行消费时,保证只有一个消费者,同时指定 prefetch 属性为 1,即每次 RabbitMQ 都只往客户端推送一个消息。像这样:
spring.rabbitmq.listener.simple.prefetch=1
而在多队列情况下,如何保证消息的顺序性,目前使用 RabbitMQ 的话,还没有比较好的解决方案。使用时,应该尽量避免这种情况。
数据堆积问题
首先在消息生产者端: 对于生产者端,最明显的方式自然是降低消息生产的速度。但是,生产者端产生消息的速度通常是跟业务息息相关的,一般情况下不太好直接优化。但是可以选择尽量多采用批量消息的方式,降低 IO 频率。
然后在 RabbitMQ 服务端: 从前面的分享中也能看出,RabbitMQ 本身其实也在着力于提高服务端的消息堆积能力。对于消息堆积严重的队列,可以预先添加懒加载机制,或者创建 Sharding 分片队列,这些措施都有助于优化服务端的消息堆积能力。另外,尝试使用 Stream 队列,也能很好的提高服务端的消息堆积能力。
接下来在消息消费者端:要提升消费速度最直接的方式,就是增加消费者数量了。尤其当消费端的服务出现问题,已经有大量消息 堆积时。这时,可以尽量多的申请机器,部署消费端应用,争取在最短的时间内消费掉积压的消息。但是这 种方式需要注意对其他组件的性能压力。
对于单个消费者端,可以通过配置提升消费者端的吞吐量。例如:
# 单次推送消息数量
spring.rabbitmq.listener.simple.prefetch=1
# 消费者的消费线程数量
spring.rabbitmq.listener.simple.concurrency=
要提升消费速度最直接的方式,就是增加消费者数量了。尤其当消费端的服务出现问题,已经有大量消息
堆积时。这时,可以尽量多的申请机器,部署消费端应用,争取在最短的时间内消费掉积压的消息。但是这
种方式需要注意对其他组件的性能压力。
当确实遇到紧急状况,来不及调整消费者端时,可以紧急上线一个消费者组,专门用来将消息快速转录。保存到数据库或者 Redis,然后再慢慢进行处理。